Visualizing the XOR Solution
How neural networks transform the problem space
Figure 6.1: Learning a Representation
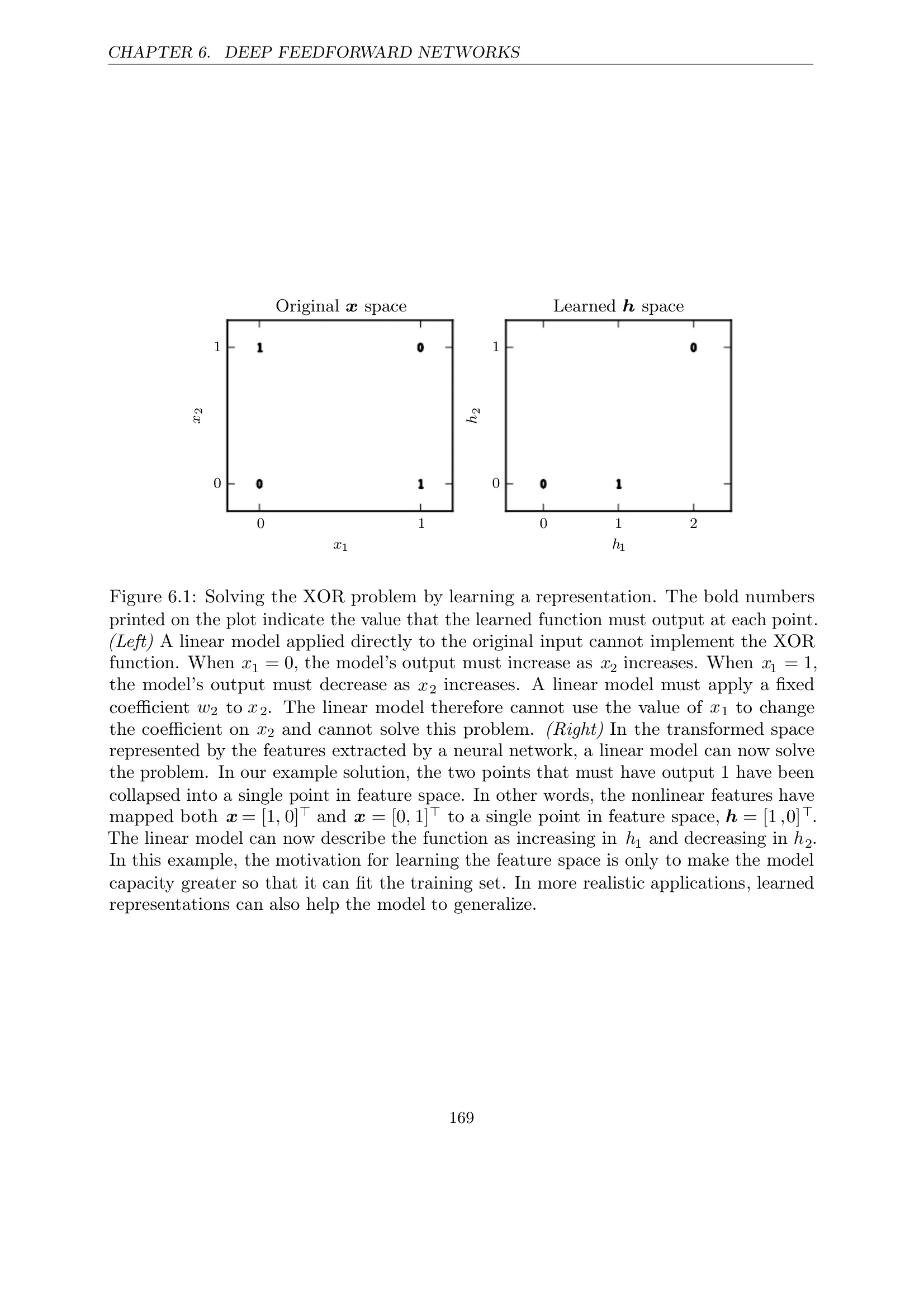
Key Insights:
- Left: Linear model cannot implement XOR in original space
- Right: In transformed space, linear model can solve the problem
- Points [1,0] and [0,1] are mapped to the same point [1,0] in feature space
- Linear model can now increase in h₁ and decrease in h₂
The nonlinear features have mapped both x = [1,0] and x = [0,1] to a single point in feature space, h = [1,0]. This transformation makes the problem linearly separable.
Figure 6.2: Network Architecture

Two Drawing Styles:
- Left: Every unit as a node - explicit but space-consuming
- Right: Vector representation - more compact
- Matrix W describes mapping from x to h
- Vector w describes mapping from h to y
Figure 6.3: ReLU Activation Function
ReLU Properties:
- Default choice for most feedforward networks
- Piecewise linear with two linear pieces
- Nearly linear - preserves optimization properties
- Good generalization properties
- Universal approximation capability
Interactive ReLU Function
Move your mouse over the graph to see values