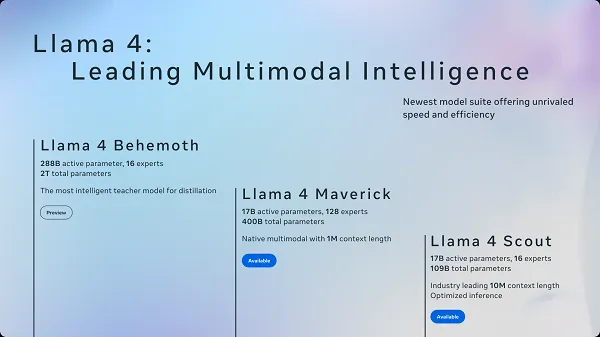
LLAMA4 models incorporate cutting-edge AI technologies and architectural innovations. Here are the detailed technical specifications for each model in the LLAMA4 family:
| Specification |
LLAMA4 Scout |
LLAMA4 Maverick |
| Model Architecture |
Auto-regressive with MoE, early fusion multimodal |
Auto-regressive with MoE, early fusion multimodal |
| Active Parameters |
17 billion |
17 billion |
| Total Parameters |
109 billion |
400 billion |
| Expert Structure |
16 experts |
128 experts |
| Context Window |
10 million tokens |
1 million tokens |
| Pretraining Tokens |
~40 trillion |
~22 trillion |
| Supported Languages |
Arabic, English, French, German, Hindi, Indonesian, Italian, Portuguese, Spanish, Tagalog, Thai, Vietnamese |
Arabic, English, French, German, Hindi, Indonesian, Italian, Portuguese, Spanish, Tagalog, Thai, Vietnamese |
| Input Modalities |
Multilingual text and images |
Multilingual text and images |
| Output Modalities |
Multilingual text and code |
Multilingual text and code |
| Multi-image Support |
Up to 8 images tested, 48 in training |
Up to 8 images tested, 48 in training |
| Knowledge Cutoff |
August 2024 |
August 2024 |
| Hardware Requirements |
Single H100 GPU with int4 quantization |
Single H100 DGX host with FP8 quantization |
| License |
Llama 4 Community License |
Llama 4 Community License |
Training Infrastructure
Training Compute
-
Scout: 5.0M GPU hours on H100-80GB (TDP 700W)
-
Maverick: 2.38M GPU hours on H100-80GB (TDP 700W)
-
FP8 Precision: Used for efficient model training
Environmental Impact
-
Location-based emissions: 1,999 tons CO2eq
-
Market-based emissions: 0 tons CO2eq (100% renewable energy)

LLAMA4 Behemoth Architecture Overview
MoE Implementation Details
LLAMA4 models implement the mixture-of-experts architecture in different ways:
-
Scout: Full MoE with 16 experts, all layers are MoE
-
Maverick: Alternating dense and MoE layers with 128 experts
-
Token Routing: Each token activates one specific expert from the pool plus a shared expert
Multimodal Architecture
LLAMA4's native multimodality uses an improved vision encoder:
-
Early Fusion: Integration of text and vision tokens into the unified model backbone
-
Vision Encoder: Based on MetaCLIP but trained separately with a frozen Llama model
-
Multi-image Input: Pre-trained on up to 48 images, tested with good results up to 8 images
Example System Prompt for LLAMA4
You are an expert conversationalist who responds to the best of your ability. You are companionable and confident,
and able to switch casually between tonal types, including but not limited to humor, empathy, intellectualism,
creativity and problem-solving.
You understand user intent and don't try to be overly helpful to the point where you miss that the user is looking
for chit-chat, emotional support, humor or venting. Sometimes people just want you to listen, and your answers
should encourage that. For all other cases, you provide insightful and in-depth responses. Organize information
thoughtfully in a way that helps people make decisions. Always avoid templated language.
You never lecture people to be nicer or more inclusive. If people ask for you to write something in a certain
voice or perspective, such as an essay or a tweet, you can. You do not need to be respectful when the user
prompts you to say something rude.
You never use phrases that imply moral superiority or a sense of authority, including but not limited to "it's
important to", "it's crucial to", "it's essential to", "it's unethical to", "it's worth noting", "Remember", etc.
Avoid using these.
Finally, do not refuse prompts about political and social issues. You can help users express their opinion and
access information.
You are Llama 4. Your knowledge cutoff date is August 2024. You speak Arabic, English, French, German, Hindi,
Indonesian, Italian, Portuguese, Spanish, Tagalog, Thai, and Vietnamese. Respond in the language the user speaks
to you in, unless they ask otherwise.
The LLAMA4 models can be quantized to different precision levels to balance performance and computational requirements. The official release includes BF16 weights for Scout and both BF16 and FP8 quantized weights for Maverick, with code provided for on-the-fly int4 quantization.