ما هو مزيج الخبراء (MoE)؟
مزيج الخبراء (MoE) هو هيكل شبكة عصبية حيث بدلاً من استخدام نموذج كثيف واحد، تتكون الشبكة من نماذج فرعية متعددة تُعرف باسم "الخبراء". يتخصص كل خبير في معالجة أجزاء مختلفة من المدخلات.
في سياق نماذج اللغة الكبيرة (LLMs)، يستبدل MoE طبقات التغذية الأمامية الكثيفة التقليدية بمجموعة من شبكات الخبراء، مما يسمح للنموذج بامتلاك عدد أكبر بكثير من المعلمات مع الحفاظ على تكاليف الحوسبة قابلة للإدارة.
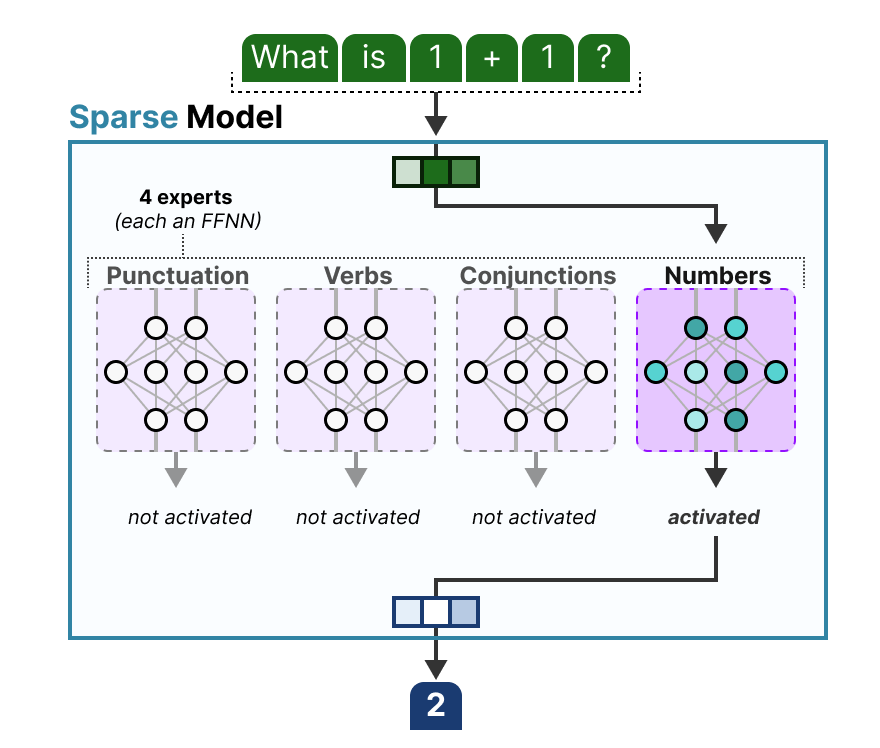
الفكرة الرئيسية لـ MoE هي أنه لأي رمز إدخال معين (مثل كلمة أو جزء من كلمة)، يلزم تنشيط جزء صغير فقط من معلمات النموذج. تتم إدارة هذا التنشيط الانتقائي بواسطة "موجه" أو "شبكة بوابة" تقرر أي الخبراء يجب أن يعالج كل رمز إدخال.
"يتيح MoE للنماذج أن يتم تدريبها المسبق بقدر أقل بكثير من الحوسبة، مما يعني أنه يمكنك زيادة حجم النموذج أو مجموعة البيانات بشكل كبير دون زيادة متناسبة في تكاليف التدريب." — مدونة Hugging Face
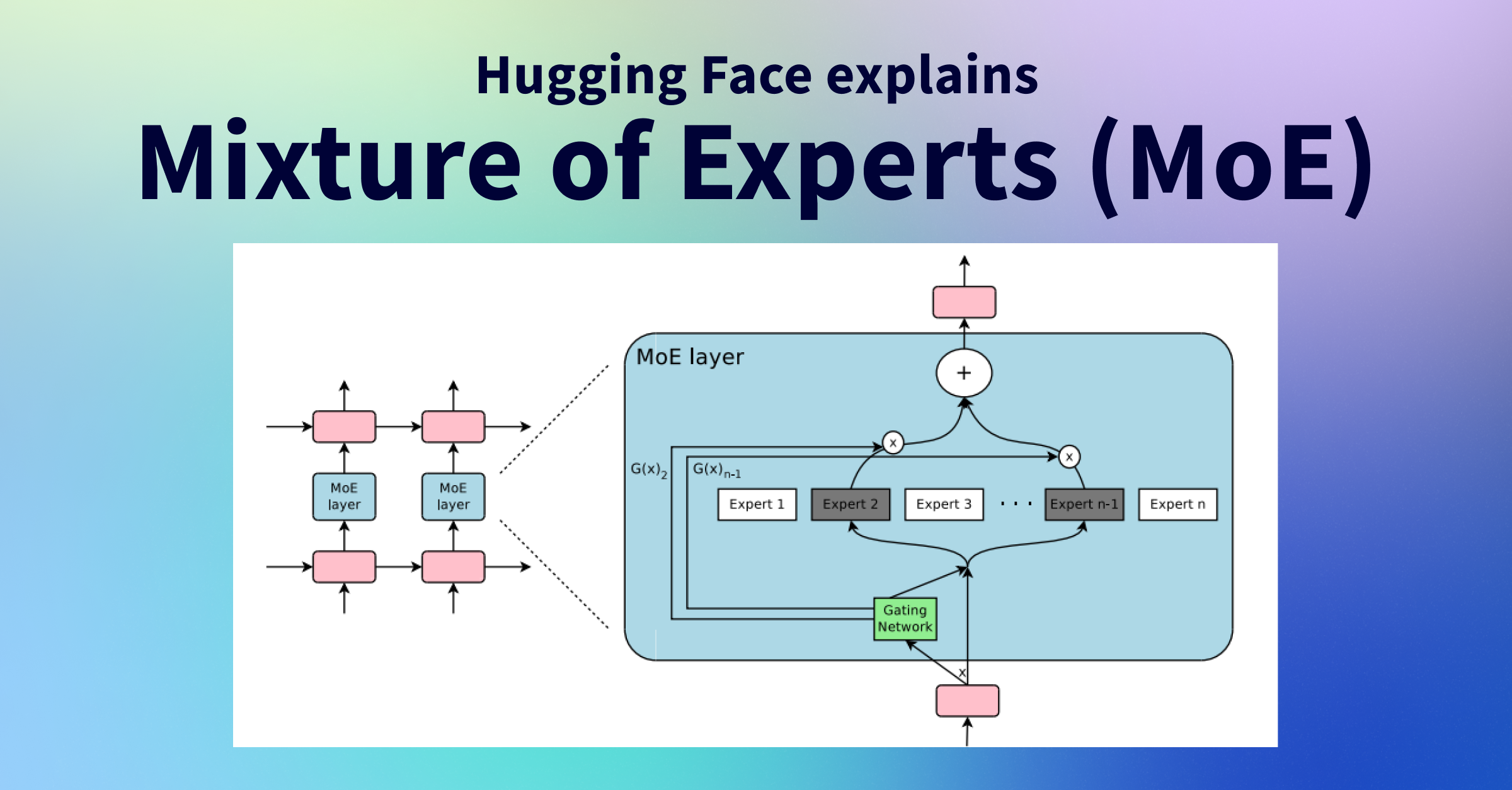
كيف يعمل MoE في نماذج اللغة الكبيرة
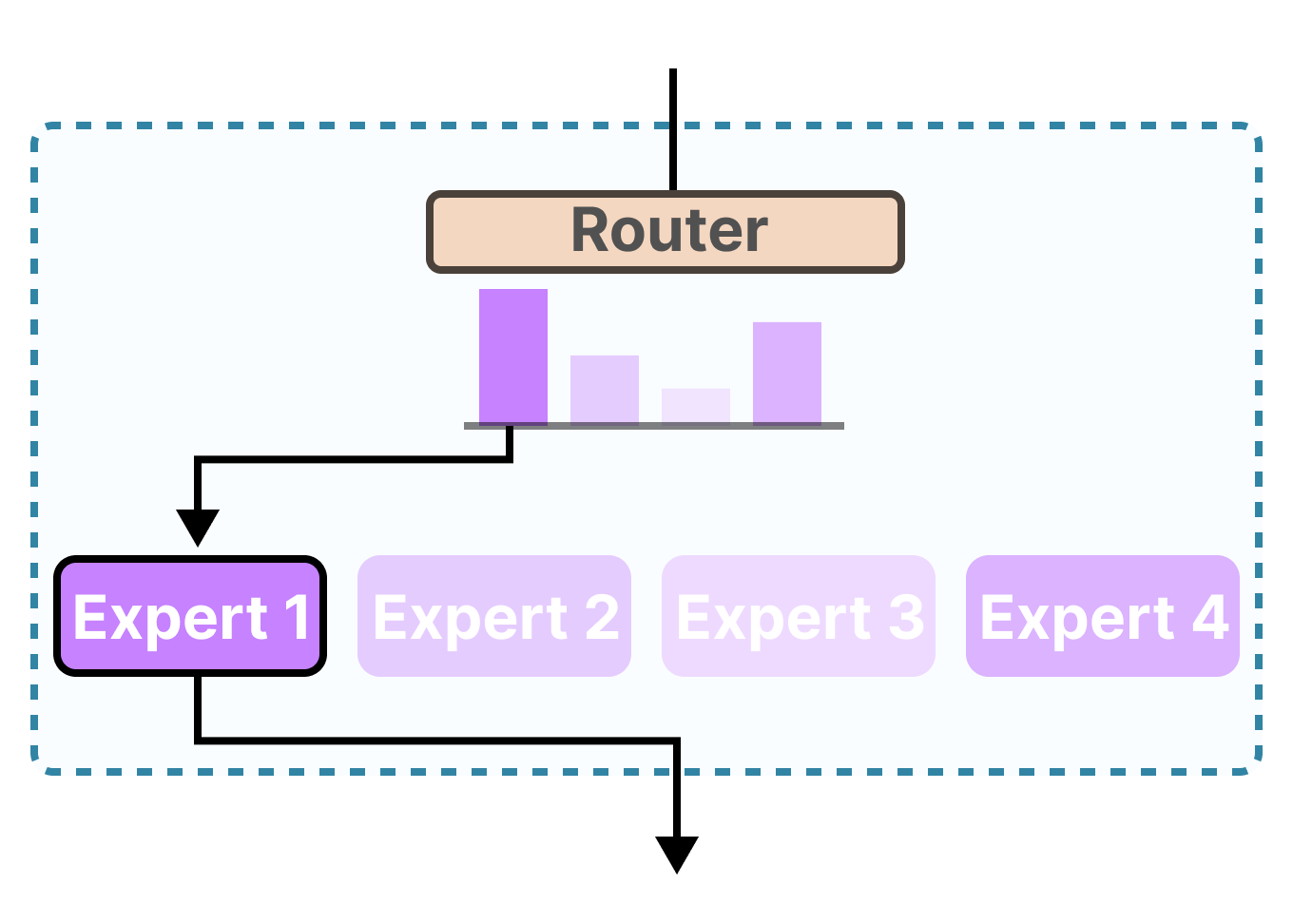
العملية خطوة بخطوة
- ١. معالجة المدخلات: يدخل رمز الإدخال (أو تضمينه) إلى طبقة MoE داخل هيكل المحول.
- ٢. تقييم الموجه: يقوم الموجه (شبكة البوابة) بحساب توزيع احتمالي على جميع الخبراء المتاحين باستخدام دالة softmax لتحديد الخبراء الأنسب لهذا الإدخال المحدد.
- ٣. اختيار الخبراء: بناءً على هذه الاحتمالات، يتم اختيار أفضل k خبراء (عادة 1 أو 2 فقط) لمعالجة الرمز.
- ٤. المعالجة المتوازية: يقوم الخبراء المختارون بمعالجة الرمز بالتوازي وإنتاج مخرجاتهم الخاصة.
- ٥. تجميع المخرجات: يتم ترجيح المخرجات من الخبراء النشطين باستخدام احتمالات اختيار الموجه ودمجها لتشكيل المخرج النهائي لذلك الرمز.
- ٦. الانتشار الأمامي: يتم تمرير المخرج المدمج إلى الطبقات اللاحقة في هيكل النموذج.
تسمح هذه الآلية للنموذج بامتلاك عدد هائل من المعلمات (معلمات متفرقة) ولكن استخدام جزء منها فقط (المعلمات النشطة) في وقت الاستدلال، مما يؤدي إلى استخدام أكثر كفاءة للموارد الحاسوبية مع زيادة قدرة النموذج.
المكونات الرئيسية لـ MoE
الخبراء
نماذج فرعية فردية، عادة ما تُنفَّذ كشبكات عصبية ذات تغذية أمامية. يتخصص كل خبير في معالجة أنواع معينة من المدخلات أو الأنماط اللغوية، مما يمكّن من تمثيلات أكثر دقة.
الخبراء في هيكل MoE مشابهون للمتخصصين في مجالات مختلفة. على سبيل المثال، قد يصبح بعض الخبراء ماهرين في معالجة المحتوى الرياضي، بينما قد يتخصص آخرون في الكتابة الإبداعية أو المصطلحات العلمية.
في معظم تطبيقات MoE، يمتلك الخبراء هياكل متطابقة ولكنهم يختلفون في المعلمات المتعلمة. أثناء التدريب، يطور الخبراء تخصصات بشكل طبيعي من خلال قرارات التوجيه التي تتخذها شبكة البوابة.
شبكة الموجه/البوابة
المكون المسؤول عن اختيار أي الخبراء يجب أن يعالج كل رمز إدخال. يقوم بحساب توزيع احتمالي على جميع الخبراء وتوجيه الرموز إلى المتخصصين الأكثر ملاءمة.
يحدد الموجه احتمالات التوجيه عن طريق حساب التشابه بين تضمين رمز الإدخال ومصفوفة وزن متعلمة. ثم تُستخدم هذه الاحتمالات لاختيار أفضل k خبراء للمعالجة.
توجد استراتيجيات توجيه مختلفة، بما في ذلك توجيه "أعلى-1" (حيث يتم اختيار الخبير الأكثر ملاءمة فقط) وتوجيه "أعلى-k" (حيث يتم اختيار خبراء متعددين بأوزان مختلفة). يؤثر قرار التوجيه بشكل كبير على أداء النموذج وكفاءة الحوسبة.
آليات موازنة الحمل
تقنيات تضمن توزيع الرموز بالتساوي بين الخبراء، مما يمنع استخدام بعض الخبراء بشكل مفرط بينما يبقى البعض الآخر غير مدرب بشكل كاف. هذه التقنيات ضرورية لاستقرار تدريب MoE.
تشمل تقنيات موازنة الحمل الشائعة:
- خسارة مساعدة: هدف تدريب إضافي يعاقب توزيعات التوجيه غير المتساوية
- سعة الخبير: تحديد عدد الرموز التي يمكن لكل خبير معالجتها في الدفعة الواحدة
- طريقة KeepTopK: فرض توزيع أكثر توازناً للرموز بين الخبراء
بدون موازنة الحمل المناسبة، يمكن أن تعاني نماذج MoE من "انهيار الخبير"، حيث يرسل الموجه معظم الرموز إلى عدد قليل من الخبراء فقط، مما يقلل النموذج فعلياً إلى نموذج أصغر بكثير.
مميزات MoE
قابلية التوسع المحسنة
يسمح MoE للنماذج بدمج مليارات المعلمات مع تنشيط جزء صغير فقط أثناء الاستدلال. هذا يتيح التوسع إلى أحجام نموذج أكبر بكثير دون زيادات متناسبة في الحوسبة.
كفاءة الحوسبة
من خلال توجيه الرموز بشكل انتقائي إلى الخبراء الأكثر صلة، يقلل MoE من العمليات الحسابية الزائدة التي تحدث في النماذج الكثيفة التقليدية، مما يؤدي إلى استدلال أسرع واستهلاك طاقة أقل رغم حجم النموذج الإجمالي الأكبر.
معرفة متخصصة
يمكن لكل خبير تطوير معرفة متخصصة لمجالات معينة أو أنماط لغوية، مما يسمح للنموذج بالحفاظ على كل من اتساع وعمق الفهم عبر مواضيع متنوعة.
كفاءة التدريب
يمكن لنماذج MoE تحقيق نفس جودة النماذج الكثيفة مع قدر أقل بكثير من الحوسبة أثناء التدريب المسبق، مما يتيح استخداماً أكثر كفاءة للموارد عند تطوير نماذج جديدة.
تخصيص موارد مرن
يسمح هيكل MoE بتخصيص ديناميكي للموارد الحاسوبية لأجزاء مختلفة من المدخلات، مع تركيز قوة الحوسبة حيث تكون أكثر حاجة لكل رمز محدد.
"يمكن مزيج الخبراء النماذج من التدريب المسبق بقدر أقل بكثير من الحوسبة، مما يعني أنه يمكنك زيادة حجم النموذج أو مجموعة البيانات بشكل كبير دون زيادة متناسبة في تكاليف التدريب."
— مدونة Hugging Face
مقارنة: النموذج الكثيف مقابل نموذج MoE
| المقياس | النموذج الكثيف التقليدي | نموذج MoE |
|---|---|---|
| المعلمات | تُستخدم جميع المعلمات لكل رمز | تُستخدم فقط معلمات الخبير المختارة لكل رمز |
| استخدام الذاكرة | متناسب مع حجم النموذج | مرتفع (يتم تحميل جميع الخبراء في الذاكرة) |
| سرعة الاستدلال | أبطأ للنماذج الأكبر | أسرع لنفس عدد المعلمات |
| حوسبة التدريب | أعلى لنفس الجودة | أقل لنفس الجودة |
| التخصص | معرفة عامة موزعة عبر النموذج | معرفة متخصصة في خبراء مختلفين |
التطبيقات في العالم الحقيقي
تم تطبيق هيكل MoE بنجاح في العديد من نماذج اللغة الكبيرة البارزة، كل منها بنهج وتحسينات فريدة:

Mixtral 8x7B
طورته شركة Mistral AI، يستخدم Mixtral 8 نماذج خبيرة بهيكل MoE متفرق. لكل رمز، يختار النموذج أفضل خبيرين ملائمين من بين 8 خبراء متاحين.
- ✓ إجمالي 46.7 مليار معلمة ولكن يستخدم فقط ~12.9 مليار لكل رمز
- ✓ يتفوق على النماذج الكثيفة الأكبر بكثير في المقاييس المعيارية
- ✓ استدلال فعال مع توجيه أفضل خبيرين
يعتمد Mixtral على هيكل Mistral 7B ولكنه يدمج طبقات MoE التي توجه الرموز إلى 2 من أصل 8 خبراء. هذا يسمح له بتحقيق أداء مماثل للنماذج الأكبر بكثير مع الحفاظ على تكاليف استدلال معقولة.
يوضح النموذج كفاءة MoE من خلال تحقيق نتائج على مستوى عالمي في مختلف المقاييس المعيارية مع الحفاظ على عدد قليل من المعلمات النشطة. يستخدم قرارات توجيه رمز برمز، مما يسمح باختيار خبير يعتمد على السياق.
اقرأ المزيد
GPT-4
وفقاً للتقارير، ينفذ GPT-4 شكلاً من أشكال MoE باستخدام 8 نماذج خبيرة أصغر بدلاً من شبكة واحدة ضخمة، مما يتيح تحسين الأداء والمعرفة المتخصصة.
- ✓ نماذج خبيرة متعددة تتخصص كل منها في مجالات مختلفة
- ✓ يُقال أنه يحتوي على 8 نماذج خبيرة بحوالي ~220 مليار معلمة لكل منها
- ✓ نظام منسق يدير التوجيه بين الخبراء
بينما لم تؤكد OpenAI رسمياً الهيكل الدقيق، تشير التقارير إلى أن GPT-4 يستخدم نهج مزيج الخبراء لتحسين الأداء وكفاءة الاستدلال.
يتضمن الهيكل المُبلغ عنه نماذج متخصصة متعددة تنسقها نظام توجيه مركزي، مما يسمح بخبرة متخصصة في المجال مع الحفاظ على القدرات العامة. يُعتقد أن هذا الهيكل يساهم في أداء GPT-4 القوي عبر المهام المتنوعة.
اقرأ المزيد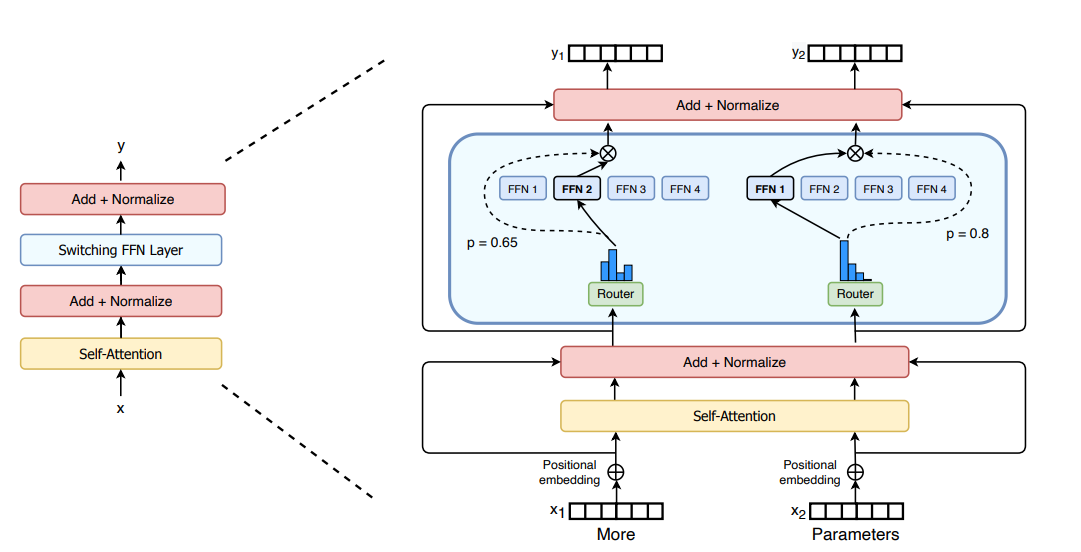
Switch Transformer
طورته Google Research، كان Switch Transformer رائداً في نهج MoE المبسط مع توجيه أعلى-1، حيث تتم معالجة كل رمز بواسطة خبير واحد فقط.
- ✓ توجيه مبسط مع خبير واحد لكل رمز
- ✓ يتوسع إلى نماذج ذات ترليون معلمة
- ✓ تقليل النفقات العامة للاتصالات مقارنة بنُهج MoE الأخرى
قدم Switch Transformer عدة تحسينات رئيسية لنهج MoE، بما في ذلك آلية توجيه مبسطة تختار خبيراً واحداً فقط لكل رمز، مما يقلل من تكاليف الاتصال وتعقيد الحوسبة.
يستخدم النموذج أيضاً تقنيات مثل الدقة الانتقائية (استخدام دقة أقل لحساب الخبير) وعوامل سعة الخبير لتحسين استقرار التدريب وكفاءته. سمحت هذه الابتكارات لـ Switch Transformer بالتوسع إلى أكثر من ترليون معلمة مع الحفاظ على تكاليف تدريب معقولة.
اقرأ المزيدتطبيقات MoE البارزة الأخرى
| النموذج | المنظمة | الميزات الرئيسية | السنة |
|---|---|---|---|
| GShard | Google Research | توجيه أعلى-2، طبقات MoE متناوبة، عامل سعة الخبير | 2020 |
| GLaM | Google Research | MoE بـ 1.2 ترليون معلمة مع 64 خبيراً لكل طبقة، تقليل 95% في حوسبة التدريب | 2021 |
| NLLB-MoE | Meta AI | نموذج ترجمة متعدد اللغات مع 1.5 مليار معلمة، دعم 128 لغة | 2022 |
| DeepSeek-MoE | DeepSeek | نموذج MoE مفتوح المصدر بـ 16 مليار معلمة مع استدلال رياضي قوي | 2023 |
التحديات التقنية
تحديات التدريب والاستدلال
متطلبات ذاكرة عالية
على الرغم من أن نماذج MoE تنشط فقط مجموعة فرعية من المعلمات أثناء الاستدلال، يجب تحميل جميع الخبراء في الذاكرة. هذا يخلق متطلبات عالية لذاكرة الفيديو (VRAM) يمكن أن تحد من خيارات النشر.
عدم استقرار التدريب
يمكن أن تؤدي آليات التوجيه في هياكل MoE إلى عدم استقرار التدريب. غالباً ما تكون الخسائر الإضافية (مثل خسارة موازنة الحمل المساعدة وخسارة z للموجه) مطلوبة لاستقرار التدريب.
تحديات الضبط الدقيق
تميل نماذج MoE إلى المبالغة في الملاءمة أثناء الضبط الدقيق بشكل أسرع من النماذج الكثيفة. تتطلب معلمات تجريبية مختلفة وأحياناً تحديث معلمات انتقائي لمنع المبالغة في الملاءمة.
تحديات معمارية
موازنة الحمل
ضمان توزيع الرموز بالتساوي بين الخبراء ليس بالأمر السهل. يمكن أن يؤدي التوجيه غير المتساوي إلى نقص استخدام بعض الخبراء مع زيادة تحميل آخرين.
نفقات الاتصال العامة
في إعدادات التدريب الموزع، تتطلب هياكل MoE اتصالاً كبيراً بين الأجهزة حيث يتم توجيه الرموز إلى خبراء قد يكونون على أجهزة مختلفة. هذا يمكن أن يصبح عنق زجاجة.
تخطيط سعة الخبير
تحديد العدد المناسب من الخبراء وسعتهم أمر بالغ الأهمية. قلة عدد الخبراء يمكن أن تحد من قدرات النموذج، بينما كثرتهم يمكن أن تؤدي إلى استخدام غير فعال للموارد.
الحلول والتخفيفات
لاستقرار التدريب
- خسارة موازنة الحمل المساعدة لتشجيع توزيع متساوٍ للرموز
- خسارة z للموجه لمنع مدخلات توجيه كبيرة وعدم الاستقرار
- تقنيات الدقة الانتقائية (استخدام دقة أقل لحساب الخبير)
- استراتيجيات إسقاط وتنظيم مصممة خصيصاً لـ MoE
لكفاءة النشر
- توازي الخبراء عبر أجهزة متعددة
- تقنيات التكميم لتقليل استخدام الذاكرة
- تقليم الخبراء لإزالة الخبراء الزائدين أو قليلي الاستخدام
- تحميل الخبراء المشروط بناءً على متطلبات المهمة المتوقعة
يستمر البحث في تطوير حلول محسنة لهذه التحديات، مما يجعل هياكل MoE أكثر عملية للنشر في العالم الحقيقي.
الاتجاهات المستقبلية
تحسينات العتاد
من المحتمل أن تركز تطبيقات MoE المستقبلية على تحسينات خاصة بالعتاد تقلل من عنق زجاجة الذاكرة والاتصالات التي تحد حالياً من النشر.
- مسرعات متخصصة لعمليات المصفوفات المتفرقة
- أنظمة تحميل الخبراء عند الطلب
- أطر إدارة الخبراء الموزعة
آليات توجيه متقدمة
يستكشف البحث استراتيجيات توجيه أكثر تطوراً تفهم بشكل أفضل المحتوى الدلالي للرموز وتتخذ قرارات اختيار خبير أكثر استنارة.
- توجيه مدرك للسياق يأخذ في الاعتبار علاقات الرموز
- تخصيص خبير ذاتي التعديل أثناء الاستدلال
- هياكل خبراء هرمية للتخصص متعدد المستويات
الهياكل الهجينة
قد تمزج النماذج المستقبلية بين MoE وتقنيات الكفاءة الأخرى لإنشاء هياكل هجينة تتغلب على القيود الحالية مع الحفاظ على فوائد تخصص الخبراء.
- الجمع بين MoE والتوليد المعزز بالاسترجاع
- دمج MoE مع مكونات استدلال معيارية
- تعديل الهيكل الديناميكي بناءً على تعقيد المدخلات
اتجاهات البحث الناشئة
تكوين الخبراء المستمر
البحث في النماذج التي يمكن أن تنشئ أو تدمج أو تقلم الخبراء بشكل ديناميكي أثناء التدريب بناءً على أنماط البيانات المرصودة، مما يسمح بتخصص أكثر مرونة.
خبراء متعددي الوسائط
استكشاف هياكل MoE التي تتعامل مع وسائط مختلفة (نص، صور، صوت) مع خبراء متخصصين لكل نوع من البيانات وتكامل عبر الوسائط.
استقرار الضبط الدقيق
تطوير تقنيات لتحسين استقرار وأداء نماذج MoE أثناء الضبط الدقيق، ومعالجة تحديات المبالغة في الملاءمة التي تُلاحظ حالياً.
نشر MoE متوافق مع السحابة
أنظمة لتوسيع نماذج MoE بشكل ديناميكي في بيئات السحابة، مع تحميل الخبراء المطلوبين فقط بناءً على أنماط الاستخدام وتحسين تخصيص الموارد.
مع استمرار البحث في هياكل MoE في التقدم، يمكننا توقع نماذج لغوية أكثر كفاءة وقابلية للتوسع وقدرة تستفيد من قوة الخبرة المتخصصة.
استكشف MoE في مشاريعك
تمثل هياكل مزيج الخبراء أحد الاتجاهات الأكثر وعداً لتوسيع نماذج اللغة بكفاءة. ابق على اطلاع بأحدث الأبحاث والتطبيقات.