What is Mixture of Experts (MoE)?
Mixture of Experts (MoE) is a neural network architecture where instead of a single dense model, the network consists of multiple sub-models called "experts." Each expert specializes in processing different types of input.
In Large Language Models, MoE replaces dense feedforward layers with a set of expert networks, allowing a model to have a much larger total parameter count while keeping per-token computation costs manageable.
The key insight: for any given input token, only a small subset of parameters needs to activate. A "router" or "gating network" decides which expert(s) process each token — enabling massive capacity with efficient inference.
"MoE enables models to be pretrained with far less compute, which means you can dramatically scale up the model or dataset size without a proportional increase in training costs." — Hugging Face Blog
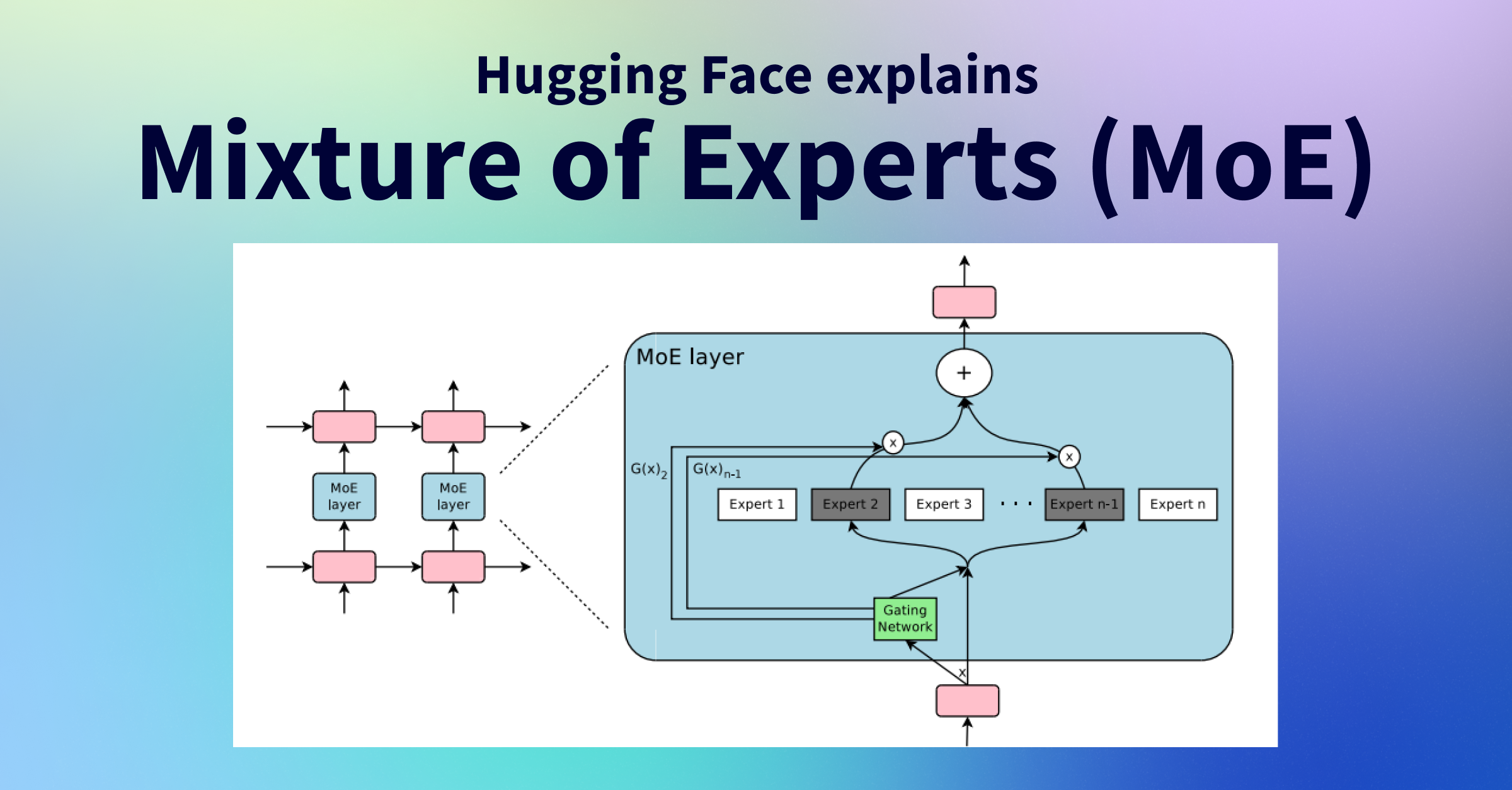
How MoE Works in LLMs
Step-by-Step Process
- 1. Input Processing: The token embedding enters the MoE layer inside the transformer block.
- 2. Router Evaluation: The gate network computes a score for each expert via a learned linear projection + softmax.
- 3. Expert Selection: Top-k experts (typically k=2) are selected per token.
- 4. Parallel Processing: Selected experts process the token independently and in parallel.
- 5. Output Aggregation: Expert outputs are combined as a weighted sum using router probabilities.
- 6. Forward Propagation: Combined output continues through the next transformer layer.
This allows models to have billions of sparse parameters while activating only a fraction per token — efficient inference at massive scale.
Key Components of MoE
Experts
Individual FFN sub-networks. Each expert learns to specialize in particular input patterns, enabling both breadth and depth of knowledge across diverse topics.
Experts in MoE are analogous to specialists: some may excel at mathematical reasoning, others at code, creative writing, or multilingual tasks.
In most implementations, experts have identical architecture but differ in learned weights. Specialization emerges naturally during training through routing decisions.
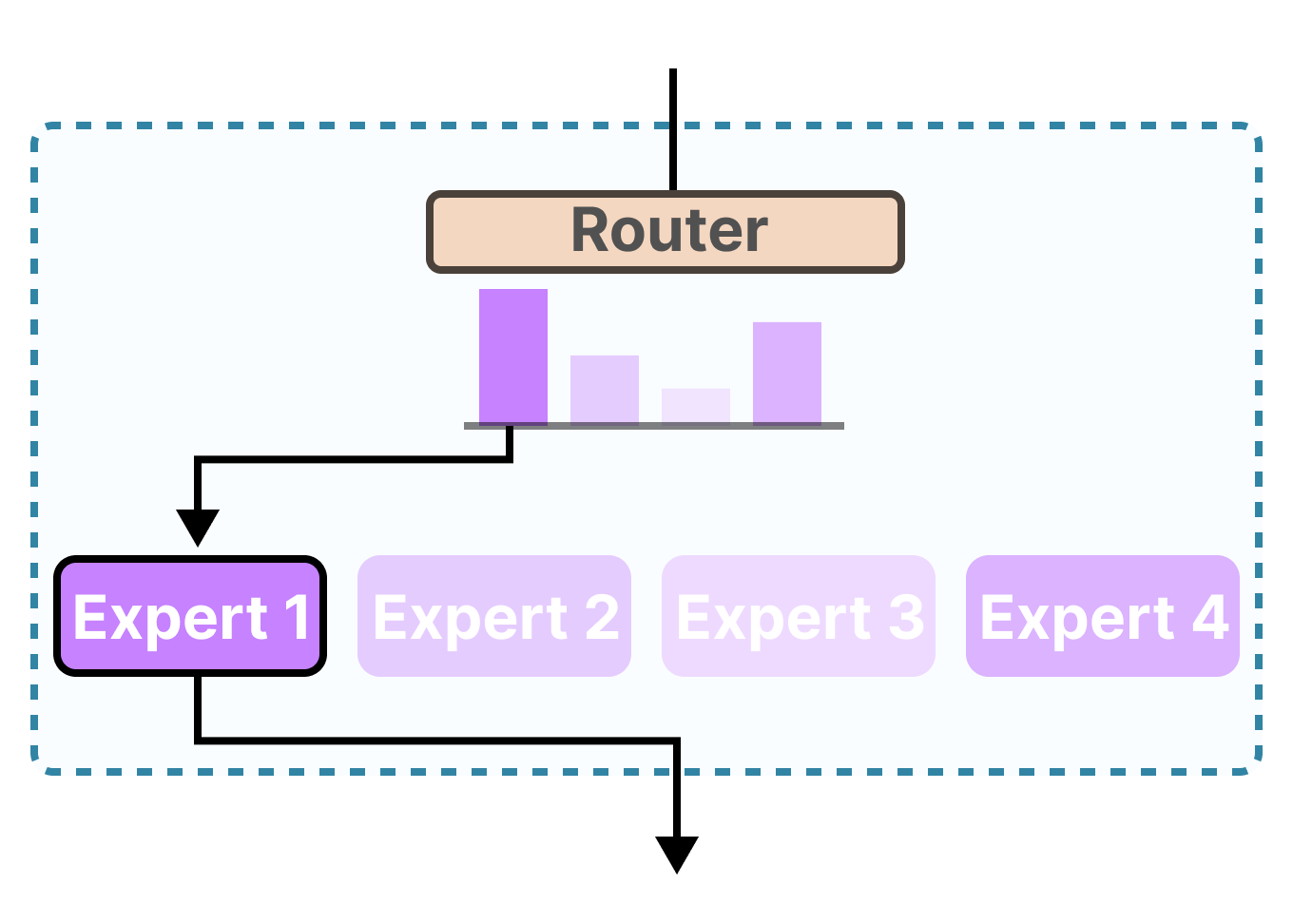
Router / Gate Network
Selects which expert(s) process each token by computing a probability distribution over all experts and choosing the top-k most relevant ones.
The router is a simple linear layer: nn.Linear(d_model, num_experts). It maps the token embedding to a score per expert, then a softmax yields probabilities.
Routing strategies: "top-1" (single expert, Switch Transformer), "top-2" (Mixtral), or "expert choice" where experts pick tokens instead of tokens picking experts.
Load Balancing
Ensures tokens distribute evenly across experts, preventing "expert collapse" where the router favors only 1–2 experts, wasting the rest.
Common techniques:
- Auxiliary loss: penalizes uneven routing distributions during training
- Expert capacity: caps tokens per expert per batch
- Router z-loss: prevents extreme routing logits (Mistral's approach)
Without balancing, most tokens flow to 1–2 experts, effectively reducing the model capacity.
Advantages of MoE
Improved Scalability
MoE models can reach hundreds of billions of parameters while activating only a fraction per token — enabling scale that would be prohibitively expensive with dense models.
Computational Efficiency
Selective routing eliminates redundant computation. DeepSeek-V3 (671B params) runs at the cost of a ~37B dense model per token — 18× parameter efficiency.
Specialized Knowledge
Each expert naturally develops specialization for particular domains — math, code, language — allowing depth and breadth simultaneously.
Training Efficiency
Mixtral 8x7B matches Llama 2 70B quality using ~5× less compute per token during pretraining. DeepSeek-V3 trained on 2.788M H800 GPU-hours — a fraction of comparable dense models.
Flexible Resource Allocation
The architecture dynamically focuses compute where it's most needed for each specific token, unlike dense models that apply uniform computation everywhere.
"Mixtral outperforms Llama 2 70B on most benchmarks while using 5× fewer active parameters per token."
— Mistral AI, 2023
Dense vs. MoE: Side-by-Side
| Metric | Dense Model | MoE Model |
|---|---|---|
| Active params per token | 100% of total | ~10–25% of total |
| Memory at inference | Proportional to size | High (all experts loaded) |
| Inference FLOP/token | High for large models | Low relative to param count |
| Training compute | Higher for same quality | Lower for same quality |
| Knowledge specialization | Uniform across layers | Expert-specific niches |
| Fine-tuning stability | More stable | Requires careful tuning |
Real-world Implementations
MoE has been adopted across the most powerful open and closed models of 2023–2025:

Mixtral 8x7B / 8x22B
Mistral AI's open-source MoE model. 8 experts per layer, top-2 routing. The 8x7B (46.7B total) uses only 12.9B active params per token, outperforming Llama 2 70B.
- ✓ 8x22B: 141B total, ~39B active — rivals GPT-4 class models
- ✓ Fully open weights, Apache 2.0 license
- ✓ Token-level routing, 32K context window
Mixtral replaces every FFN layer in a Mistral-7B-style transformer with 8 experts. For each token, the router picks top-2 experts and combines their outputs with normalized softmax weights.
The 8x22B variant (April 2024) features 65B active params for complex tasks with a 64K context window, matching GPT-4 on coding and reasoning benchmarks.
DeepSeek-V3 (2024)
DeepSeek's open-source flagship MoE. 671B total parameters, 37B active per token with 256 experts per layer and top-8 routing. Tops most open-source benchmarks.
- ✓ Multi-Head Latent Attention (MLA) for KV cache efficiency
- ✓ Trained on 14.8T tokens for $5.5M — remarkably cheap
- ✓ Matches GPT-4o on coding (HumanEval 90.2%)
DeepSeek-V3 introduces an auxiliary-loss-free load balancing strategy via learned bias terms added to routing logits, avoiding the trade-off between balance and performance.
Also uses FP8 mixed-precision training and a novel multi-token prediction auxiliary task that boosts benchmark performance at no extra inference cost.
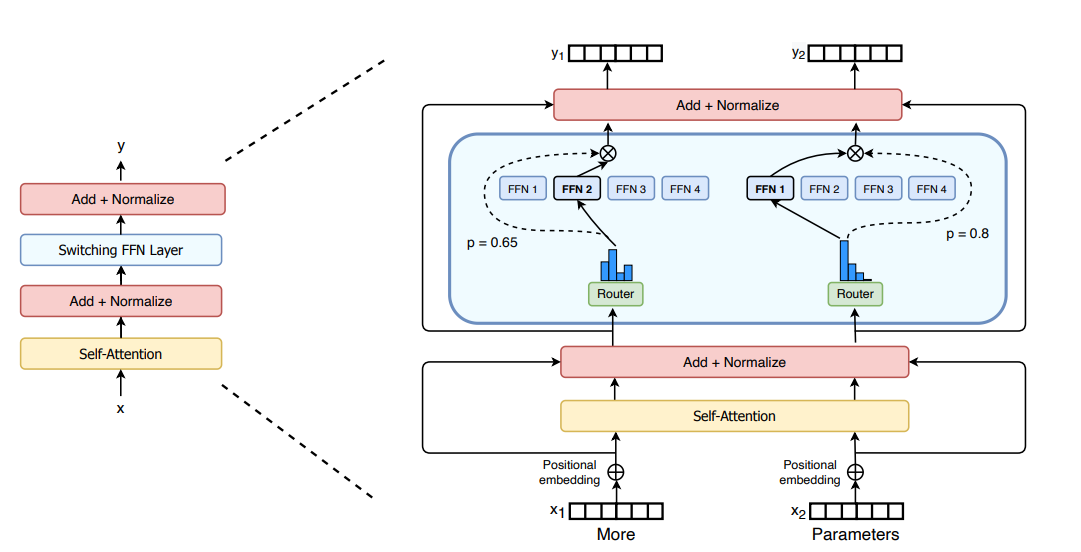
Switch Transformer (Google)
Google Research's pioneering MoE transformer (2021) that proved the viability of trillion-parameter sparse models using simple top-1 routing.
- ✓ Top-1 routing: one expert per token, maximum simplicity
- ✓ Scales to 1.6 trillion parameters
- ✓ 7× speedup vs T5-XXL at same compute budget
Switch Transformer simplified MoE by routing each token to exactly one expert, reducing communication overhead. Key innovations: expert capacity factor, selective precision, and auxiliary load balancing loss.
This paper established the modern MoE recipe and proved that routing instability could be solved at scale.
Read the paperMoE Model Timeline (2020–2025)
| Model | Organization | Architecture | Year |
|---|---|---|---|
| GShard | Top-2, alternating MoE layers, expert capacity | 2020 | |
| Switch Transformer | Top-1, 1.6T params, load balancing loss | 2021 | |
| GLaM | 1.2T params, 64 experts/layer, 95% compute reduction | 2021 | |
| NLLB-MoE | Meta AI | Translation MoE, 1.5B active, 128 languages | 2022 |
| Mixtral 8x7B | Mistral AI | 8 experts, top-2, 46.7B total / 12.9B active | 2023 |
| Grok-1 | xAI | 314B total, 8 experts, top-2, fully open weights | 2024 |
| Mixtral 8x22B | Mistral AI | 8 experts, top-2, 141B total / 39B active, 64K ctx | 2024 |
| Qwen1.5-MoE | Alibaba | 14.3B total, 2.7B active, 1/4 training cost of 7B dense | 2024 |
| DeepSeek-V2 | DeepSeek | 236B total, 21B active, MLA + fine-grained MoE | 2024 |
| DeepSeek-V3 | DeepSeek | 671B total, 37B active, 256 experts/layer, top-8 | 2024 |
Code Examples — Build MoE Step by Step
Follow these five steps to build a complete Mixture of Experts layer in PyTorch from scratch, then see how to use a production MoE model via HuggingFace.
Each "expert" is just a two-layer feedforward network, identical in structure to the FFN inside a standard transformer block. They only differ in their learned weights.
In a model with 8 experts you'd create 8 of these with nn.ModuleList — each will learn different specializations during training.
The router is a single learned linear layer that maps each token embedding to a score for every expert. Top-k scores select which experts run.
Now put it all together. The MoE layer takes a sequence of tokens, routes each one to its top-k experts, runs them in parallel (grouped by expert for efficiency), and returns the weighted sum of outputs.
Without a load balancing term, the router quickly learns to send all tokens to 1–2 experts, wasting the rest. This auxiliary loss penalizes uneven expert utilization and is added to the main training loss with a small coefficient (typically 0.01).
You don't need to build MoE from scratch to use it. HuggingFace Transformers ships Mixtral and other MoE models out of the box. Here's how to load and run them:
Tip — Small MoE model for experimentation
Use mistralai/Mixtral-8x7B-v0.1 for the base model or deepseek-ai/deepseek-moe-16b-chat for a smaller DeepSeek variant that fits on a single 24GB GPU.
Technical Challenges
Training & Inference
High Memory Requirements
Although MoE activates only a subset of parameters per token, all experts must reside in VRAM. Mixtral 8x7B needs ~90 GB FP16 — requiring 4-bit quantization for most hardware.
Training Instabilities
The discrete routing decisions (non-differentiable top-k) can cause gradient instability. Auxiliary losses, router z-loss, and careful initialization are required.
Fine-tuning Challenges
MoE models overfit faster than dense models during supervised fine-tuning. Techniques like LoRA applied only to router/non-expert weights help stabilize it.
Architecture & Deployment
Load Balancing
Without active balancing, routers collapse to using 1–2 experts for everything, wasting model capacity. Auxiliary losses and capacity factors are essential.
Communication Overhead
In distributed training, tokens must be sent to experts on different devices (all-to-all communication). This latency can bottleneck training throughput by 30–50%.
Expert Capacity Planning
Token drops occur when an expert receives more tokens than its capacity budget. Overflow tokens are dropped, potentially hurting quality. Capacity factor tuning is non-trivial.
Solutions & Mitigations
Training Stability
- Auxiliary load-balancing loss (Switch Transformer)
- Router z-loss to prevent extreme logits (ST-MoE)
- Bias-based load balancing without auxiliary loss (DeepSeek-V3)
- Selective precision: FP32 for router, FP16/BF16 for experts
Deployment Efficiency
- 4-bit / 8-bit quantization (bitsandbytes, GPTQ, AWQ)
- Expert parallelism: each GPU holds a subset of experts
- Flash Attention + MLA (Multi-Head Latent Attention) for memory
- vLLM and TensorRT-LLM for optimized MoE inference serving
Future Directions
Hardware Co-design
Next-gen accelerators will optimize for sparse expert dispatch patterns — reducing the all-to-all communication overhead that currently limits MoE training throughput.
- Sparse tensor cores for expert computation
- NVLink bandwidth optimized for expert parallelism
- On-demand expert paging from CPU ↔ GPU
Advanced Routing
Beyond simple top-k: smarter routing that understands semantic context, task type, and language, enabling better expert specialization and lower token drop rates.
- Expert-choice routing (experts select tokens)
- Soft/differentiable routing mechanisms
- Auxiliary-loss-free load balancing (DeepSeek-V3 style)
Multimodal MoE
MoE architectures naturally extend to multimodal models — vision, audio, and text can each have dedicated experts, with cross-modal experts for integration.
- Modality-specific expert clusters
- Combining MoE + RAG for grounded generation
- Dynamic expert merging / pruning post-training
Emerging Research Trends (2025)
Expert Merging & Model Soup
MoE experts can be merged post-training to create compact dense models. Techniques like DARE and TIES-merging enable knowledge distillation from MoE → dense without retraining.
Long-context MoE
Combining MoE with sliding window attention (Mixtral) and Multi-Head Latent Attention (DeepSeek) enables 128K+ context windows at manageable memory cost.
MoE for Reasoning Models
Chain-of-thought and RLHF training (GRPO, DPO) combined with MoE architectures. DeepSeek-R1 uses MoE + reinforcement learning for state-of-the-art mathematical reasoning.
Efficient On-device MoE
Small MoE models (Qwen-MoE, MobileMoE) target on-device deployment — using sparse activation to run large-capacity models on mobile GPUs and Apple Neural Engine.
Explore MoE in Your Projects
Sparse Mixture of Experts is the dominant scaling paradigm for 2024–2025. Whether you're training from scratch or fine-tuning open models, MoE gives you more capability per FLOP than any dense alternative.